
前任者と連絡が途絶えたシステムを4回発注で立て直した情シス代行事例|障害診断と保守継承
制作内容
「動いていたはずのシステムが、週末に急に止まった」現場の話
「前任の開発者と連絡が取れない」「社内に詳しい人がいないシステムが、よりによって週末に止まった」。受託開発を使ってきた事業者なら、決して他人事ではない状況だと思います。
今回ご紹介するのは、テレマーケティング系アプリを運営するクライアントから、4回の発注を経て段階的に保守を引き継いだ事例です。最初のご相談は 「週明けまでに復旧してほしい、ただし予算はなるべく抑えたい」 という、時間も予算も同時に絞られた状況で入ってきました。
この記事の主軸は、短納期対応そのものの自慢ではなく、「週明けまでの復旧」「予算最小化」という制約条件下で、何を直し、何を後回しにし、何を提案しなかったかという優先順位設計 です。
クライアント概要
- 業種: テレマーケティング系SaaS運営者(中小規模)
- 状況: 既存システムを前任の開発者に外注していたが、保守の引き継ぎが行われないまま稼働していた状態
- クライアント側に技術情報の把握なし:「とにかく動いていた」状態から「動かなくなった原因が分からない」状態に陥っていました
課題・依頼背景(Before)
- 前任との連絡が途絶えている: ドキュメント・コードの全容が断片的
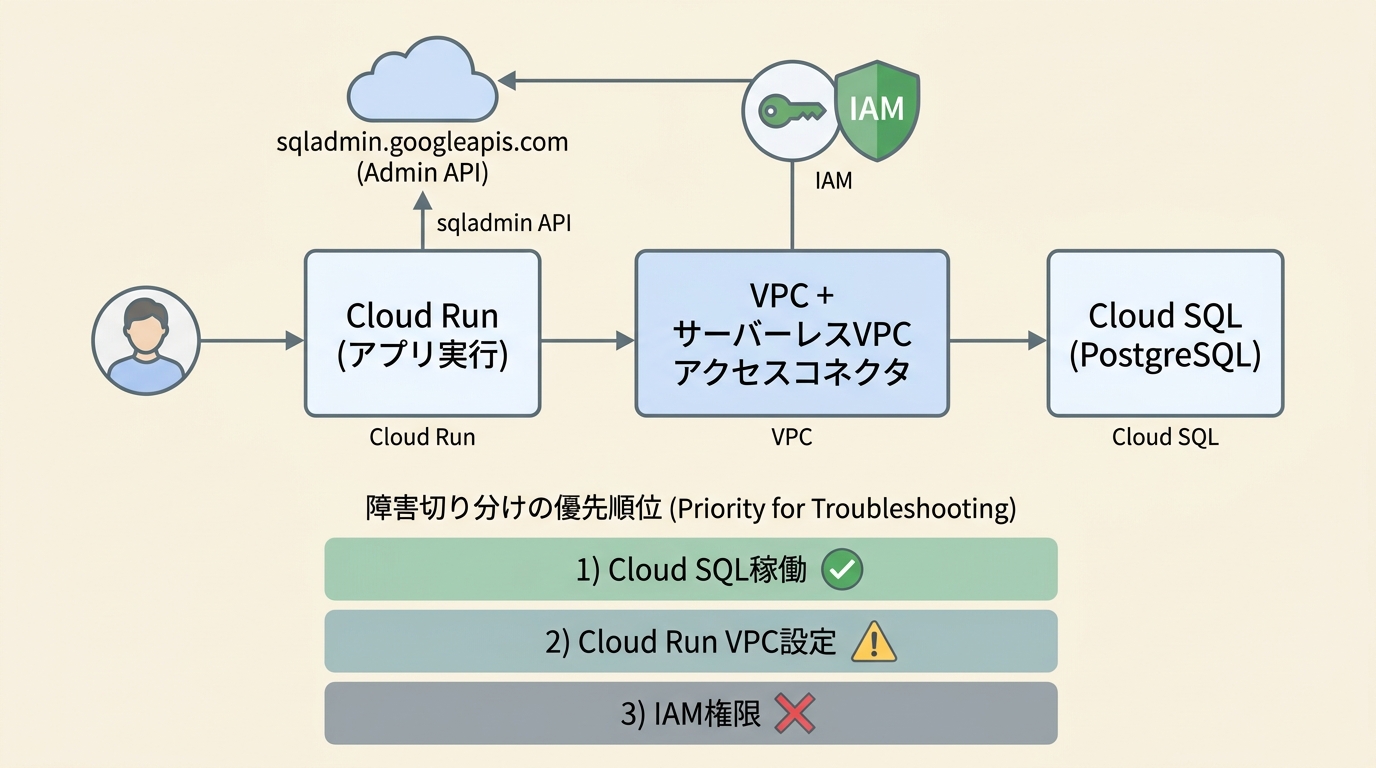
- Cloud Run側のエラーで500応答:
sqladmin.googleapis.comへの通信がタイムアウトし、Cloud SQLへの経路情報が取れない状態 - 原因の切り分けができない: アプリ側か、Cloud Run/VPC側か、Cloud SQL側か、社内に判断者がいない
- 時間制約: 週明けまでに業務が回る状態にしたい
- 予算制約: 予算はなるべく抑えたい。本当に必要な範囲に絞ってほしい
時間と予算の二重制約が乗っている以上、止めてから直すという選択肢も、網羅的に直すという選択肢も、最初から外れていました。
提案・解決アプローチ(思考プロセスを見せる)
「週明けまでの復旧」「予算最小化」の2制約のもとで、まず「今回手を入れる範囲」と「今回触らない範囲」を線引きしました。
制約条件下での優先順位設計
- 最優先(状況に合わせた優先対応・最小コスト): 500エラーの直接原因の特定と暫定復旧
- 次点(復旧後、別発注で): 構成把握・仕様書再構築・恒久対策
- 今回見送り: 全面リプレース/クラウド移行/機能追加
クライアントが求めているのは完璧な保守体制ではなく、まず週明けに業務が回ること。この理解を握り、やらないことを大量に決めたことが起点でした。
案A: 全面リプレース(不採用)
将来の安心感はある一方、着手から完了までの間に現行が止まる懸念と予算膨張リスクが大きい。「短期復旧・予算最小化」の制約下では最後の手段です。
案B: 段階発注で保守を引き継ぐ(採用)
1案件を4回の発注に分割しました。
- 第1段階(制約条件下での優先対応): 障害復旧。Cloud Run・VPC・サービスアカウント権限を調査し、最小コストで復旧
- 第2段階(後日別発注): 構成把握、Cloud Run/SQL/VPCコネクタの動作経路をドキュメント化
- 第3段階(別発注): 仕様書再構築
- 第4段階(別発注): 改修と運用整備、保守体制引き渡し
1回で全部受けず、必要性を実感したタイミングで段階発注に分けたことが、「予算を抑えたい」への一番素直な応答でした。
あえて採用しなかった選択肢
- 全面リプレース: 現行を止めるリスクと予算膨張リスクが大きすぎる
- GCPから他クラウドへの全面移行: 動いている前提を壊さない
- 「この際だから」的な機能追加提案: 本筋の安定化が後回しになり、予算条件も崩れる
- 網羅的な予防保守の同時提案: 予算条件を守れなくなるため、本当に必要な範囲に絞った
時間と予算が同時に絞られている案件では、「やらないこと」を決めることが最大の価値提供になります。
実装内容
技術スタック・対応領域
- 障害切り分け: Cloud SQL稼働ステータス、Cloud RunのVPC Egress設定、サーバーレスVPCアクセスコネクタ、サービスアカウントのロール付与の順に調査
- 構成把握:
gcloudコマンドで設定を一通り確認し、Cloud Run / Cloud SQL / VPC / サービスアカウントの関係を外形仕様としてドキュメント化 - コミュニケーション: 原因の切り分けを技術用語に偏らず日本語で随時報告
工夫した点
- 「いま壊れている」と「いずれ壊れそう」を分けて報告
- 判断できる粒度の報告: 「次に何を判断するか」中心に
- 証跡を残す: 後日の振り返りに耐える形でログ保存
成果
- 週明けまでに障害復旧を達成: クライアント条件を守り、業務が回る状態へ戻した
- ココナラで4回の継続発注: 障害対応/構成把握/仕様書整備/追加改修と段階発注をいただいた
- 保守継承資料の整備: 属人化のリスクを下げた
「止まったらすぐ相談できる相手がいる」という安心感が、繰り返し発注の理由になっていると感じています。クライアントから複数回追加発注をいただけたこと自体が成果指標です。
私の働き様
β:検討プロセス(一人称で振り返り)
エピソード1:リプレース提案を選ばなかった理由(→ ビジネスに寄り添う/ちゃんと動く)
技術者目線では「設計から作り直したほうが綺麗」な現場でしたが、「綺麗な設計」のために事業を止め、予算を膨らませる提案はしない、という線をまず引きました。提示された条件を守ることを最優先する順番です。
エピソード2:「全部直します」と言わなかった理由(→ ちょうどいい/思考プロセス)
全部に手を入れる提案は、結局何も終わらないし、予算条件を守れない。「いま壊れている部分」と「いずれ壊れそうな部分」を分け、今回直すのは前者だけと決めて報告しました。1案件を4回の発注に分けたことが継続発注の信頼につながりました。
エピソード3:仕様書を残すことを選んだ理由(→ ビジネスに寄り添う/ちゃんと動く)
「直しました、終わりです」で終わらせず、「次に誰かが触る前提」のドキュメントを残しました。同じ「前任と連絡が取れない」状態を、自分が次の前任にならないために必要な工程でした。
α:コミュニケーション抜粋(自分の発言だけ)
「『週明けまでに復旧、予算は抑えたい』というご条件、承知しました。直す範囲をできる限り小さく絞り、構成把握や仕様書整備は別フェーズに切り出します。」
「原因はCloud Run側のネットワーク設定/サービスアカウント権限起因の可能性が高いです。最小の変更で、週明けには業務が回る状態を目指します。」
「次に同じことが起きた時のために、調査ログと現状の構成をテキストで残します。次の担当者がここから引き継げる状態にしておきます。」
クライアントから提示された制約条件(時間・予算)を守ること自体が、信頼の核になります。
学び・横展開
- 事業を止める提案は最後の手段
- クライアントから提示された制約条件(時間・予算)を絶対に守る: 技術判断より先に固定する
- 直す範囲を小さく握り、1案件を複数発注に分ける
- 次の担当者が引き継げる状態を残す
前任の開発者と連絡が取れない、社内に詳しい人がいないという状況は中小企業のシステム運用で頻繁に起きます。小さな範囲から段階的に保守を引き継ぐのが、現実的で再現性のある進め方です。
関連サービス
「前任と連絡が取れないシステムを引き継いでほしい」「全面リプレースではなく、現行を活かす形で改修を相談したい」という方は、以下のサービスをご覧ください。
- 情シス代行サービス: 既存システムの障害対応・保守継承・運用改善まで月額制でお任せいただけます → /services/it-outsourcing/
ビジネスに寄り添う改修を相談したい方は、まずは無料相談からお声がけください。
Others
その他の制作実績